Choose your region, country/territory, and preferred language
Amplicon Sequencing
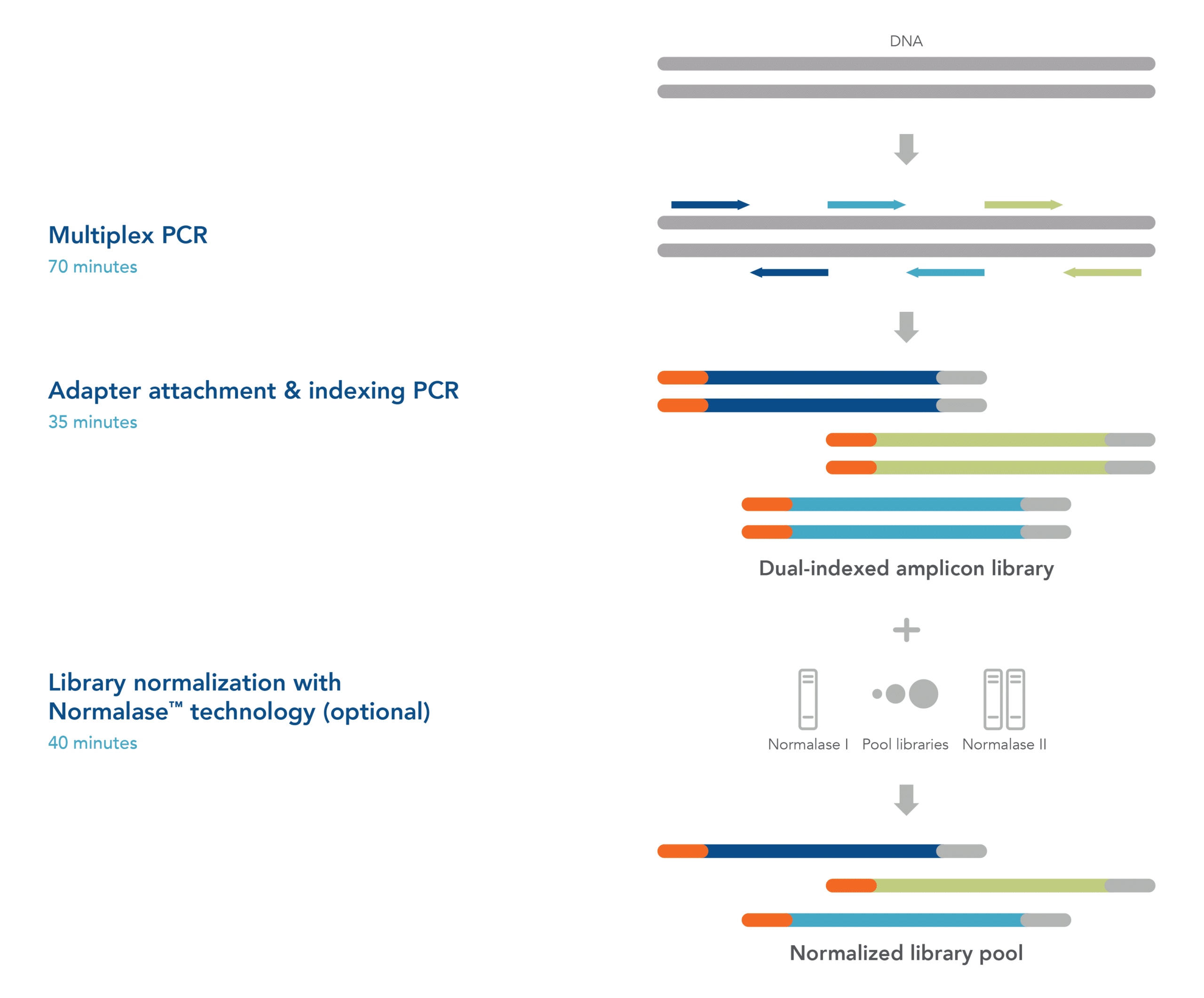
Quickly sequence hundreds or thousands of targets with a single-tube, two-hour workflow. Our automation-friendly xGenTM targeted sequencing panels deliver uniform coverage and on-target reads, even from low-input samples.